Training Materials
We strive for high quality data and data services, making data FAIR - findable, accessible, interoperable and reusable. For an introduction to the FAIR Guiding Principles see the Scientific Data paper.
In our collection of training and information materials, we inform you on the many aspects of data management.
The Data Life Cycle, DLC
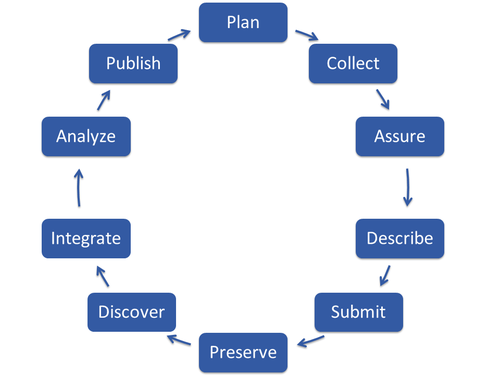
Our 10-step data life cycle is a conceptual tool to break down and bundle tasks and information on data management. A thorough introduction can be found here.
Data Management Plan, DMP
Why you' re alyways better off with a DMP:
Have a look at our GFBio Model DMP or find further examples of data management plans and checklists:
Work with your data
In this section we collected a bunch of useful tips and materials that help you deal with your data during the active project phase.
Finding, Understanding and Describing Data
Learn why semantics and terminologies are important to make your data findable:
How GFBio's semantic search can improve your search results (screencast)
"Metadata is a love note to the future" (Jason Scott, @textfiles)
...to your future self, and to others who still want to make sense of your data in a few years.
Metadata, can be considered as data about data and summarize all necessary information about data in a structured way to make the data understandable and machine readable. They should at least contain information on the data collector/owner, the content of the data, time and place of data collection, and the collection method - WHO? WHAT? WHEN? WHERE? HOW?.
Metadata
To get a first idea about what structured, and thus machine readable metadata means, the concept of attribute-value pairs might be helpful. Imagine you collect metadata information in a table. You could write the descriptors (attributes) into the header row, and the corresponding values in the second row. Be careful not to use special characters or spaces.
That’s it! Your metadata are machine readable and can be mapped onto a respective metadata standard prior to the archival of your data in a long-term repository.
Even better: Use a metadata standard right away! Metadata standards are usually written in the so-called extensible markup language (XML), a markup language for the display of hierarchically structured data in text file format. The principle is similar to the attribute-value pair concept except that in XML, the values are enclosed by an attribute’s opening and closing element:

For biological and ecological data, there are several metadata standards that can be used, depending on the type of data. For instance, for biodiversity collection data the ABCD (Access to Biological Collection cata) standard is commonly used, whereas for ecological data the EML (Ecological Metadata Language) standard can be used. For molecular sequence data, a common standard ist the MIxS (Minimum Information on any(x) Sequence) standard. All these are supported by GFBio.
Data Cleaning, File (Re)naming, Version Control

Find an example script on cleaning data with R, e.g. correcting different notations, here cast as soil horizon labels treated with regular expressions. Other example scripts will follow.
In order to cover the right problems and challenges, we welcome corresponding feedback.
If you are not familiar with R or are more comfortable working visually with your to-be-cleaned data in a spreadsheet style tool, check out the open source data cleaning tool openRefine. For an introduction see the Library Carpentry lesson.
Open Source Platforms for Biodiversity Data Management
GFBio cooperates with two German developer groups that provide open source platforms for biodiversity data management: Diversity Workbench (DWB) & BEXIS2.
If you are looking for recommended data structures, find some examples of our partners. Using them will simplify your data submission to GFBio.
Data submission templates for biodiversity, ecological and collection data
Further Ressources
Videos
GFBio features a youtube channel
see, for example: Why be(e) part of GFBio
Comprehensive Primers on Reserch Data Management
An Introduction to Data Management Reader_GFBio_BefMate_20160222 booklet, co-produced by GFBio and the BEFmate project, covering the entire data life cycle, and exemplifying data management with BExIS 1
DataOne Primer on Data Management: What you always wanted to know: Primer by DataONE describing a few fundamental data management practices that will enable you to develop a data management plan and to effectively create, organize, manage, describe, preserve, and share data.
A guide to data management in ecology and evolution: Booklet by the British Ecological Society
A guide to reproducible code in ecology and evolution: Booklet by the British Ecological Society
Relevant Guidelines related to Research Data Management
DFG Code of Conduct Guidelines for Safeguarding Good Research Practice
DFG Guidelines on the handling of Research Data
DFG Guidelines on the handling of Research Data in Biodiversity Research
Horizon 2020 and EC Open Research Pilot
General information on research data management in Germany
https://www.forschungsdaten.info/
https://www.forschungsdaten.org/index.php/Hauptseite
E-Learning Training Ressources and Courses
FOSTER open science portal: collection of training ressources related to open science with a section on research data management
de.NBI Online Training and Media Library: collection of bioinformatics training ressources provided by the German Network for Bioinformatics Infrastructure
Coursera beginnners’ course Research Data Management and Sharing